In HW4, you wrote python code that processed a text file and produced a report on character types in the file. For this assignment, you will expand on that example to generate a comprehensive report on word and letter usage. In theory, such a literary fingerprint could provide insight into an author's methods and could also help to identify the author of anonymous or disputed works of literature. The report generated by your code must include:
To make things easier, we will make some simplifying assumptions. We will assume that any sequence of characters, delineated by whitespace, that ends in a terminal punctuation mark (. ! ?) or a terminal punctuation mark followed by a quote (." !" ?" .' !' ?') designates a sentence. This may lead to some counting errors, such as I climbed Mt. Shasta. counting as two sentences. However, these counting errors may balance out, as sentences that end with brackets (e.g., [He whispered quietly.]) will not be counted. Likewise, we will assume that any sequence of characters, delineated by whitespace, that contains at least one letter is a word. For example, "2023" would not count as a word since it contains no letters, but "202x" would count as a word of length 1.
Due to these simplifying assumptions, it is possible for a file to have 0 sentences (e.g., if all punctuation marks are enclosed in brackets) or even 0 letters (e.g., if the file contains only numbers). Your code should not crash in extreme cases such as these but should either print a warning message or simply omit displaying any ill-defined statistics.
Finally, note that you are asked to report the number of letters in the file, not the number of characters. You should ignore non-letters (e.g., whitespace, punctuation marks, digits) when calculating this total. Likewise, the average word length and the definitions of short and long words depend on the number of letters, not the number of characters. This ensures that punctuation marks do not count in word lengths (e.g., end! should count as a 3-letter word).
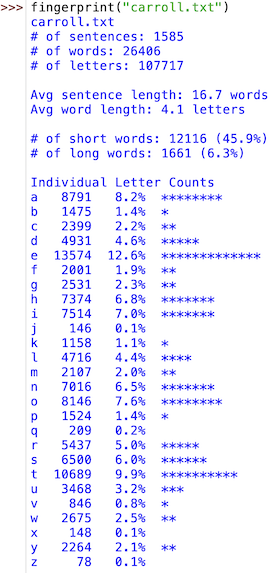
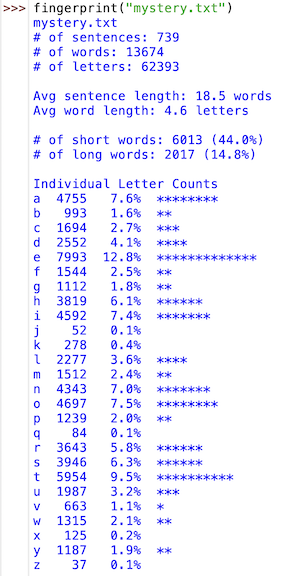
Your main function, call it fingerprint, should take the filename as input and display all of the statistics described above. Since this function may become long, you may want to write some helper functions that are called by fingerprint to carry out supporting tasks (e.g., printing the letter frequency table). All averages and percentages should be rounded to one decimal place, and all letter frequency stats should be aligned in columns. For example, the execution on the left shows the fingerprint statistics for Lewis Carroll's Alice's Adventures in Wonderland. The execution on the right shows the fingerprint statistics for a short story by an unidentified author.
You should test your code on small files for which you can hand-calculate stats. Once you are confident it works as desired, you can test your code on the following public-domain texts:
It so happens that mystery.txt was written by one of the five authors listed above: Carroll, Melville, Poe, Shakespeare, or Twain. Compare the fingerprint statistics for this short story with the five known works and try to predict the unidentified author. In a separate document, include the fingerprint statistics for the author you have chosen, and provide a brief rationale for why you think this fingerprint best matches the mystery fingerprint.